




مسائل و کاربردهای مختلفی که نهایتا به انجام داده کاوی منجر می شوند، در چند گروه اصلی قابل تقسیم بندی هستند. در ادامه، در کنار ذکر نام و معرفی اجمالی این گروه ها، کاربردهای آن ها نیز، با چند مثال بیان شده اند.
-
طبقه بندی یا Classification:

یکی از مهم ترین قابلیت هایی است که انسان ها آن را یاد می گیرند و بخش مهمی از دانش انسان، دقیقا به همین قابلیت بر می گردد و بخش اعظمی از دانش (هم به معنای عام هم به معنای آکادمیک)، به صورت طبقه بندی قابل مدل سازی هستند.
مثلا، یک پزشک پس از معاینه یک مراجعه کننده، با مشاهده شرایط وی و انجام برخی اندازه گیری ها، او را در یکی از طبقه ها یا کلاس هایی که قبلا با آن ها آشنا شده است، طبقه بندی می کند؛ مثلا «گروه افراد سالم»، «گروه افرادی که مبتلا به سرما خوردگی هستند» و یا «گروه افرادی که دچار حساسیت فصلی هستند». سپس، پزشک با مراجعه به آموخته هایش، نسخه مربوط به کلاس مربوطه را، البته با برخی ملاحظات، برای فرد مراجعه کننده می نویسد.
همین فرایند، با استفاده از روش های یادگیری ماشین (Machine Learning)، به طور خاص روش های یادگیری نظارت شده (Supervised Learning)، توسط الگوریتم های محاسباتی قابل پیاده سازی و شبیه سازی است. مثلا، وقتی یک سیستم پیشنهادگر در یک فروشگاه آنلاین به کاربری پیشنهاد خرید یک کتاب رمان را می دهد، یکی از روش های احتمالی برای انجام این کار این است که، سیستم مشتریان را طبقه بندی می کند و برای هر طبقه (یا کلاس)، پیشنهادهای خاص خودش را ارائه می دهد. یعنی اگر آمازون به شما پیشنهاد خرید یک کتاب رمان را می دهد، از نظر سیستم پیشنهادگر، شما در کلاس افرادی که رمان می خوانند، طبقه بندی می شوید.


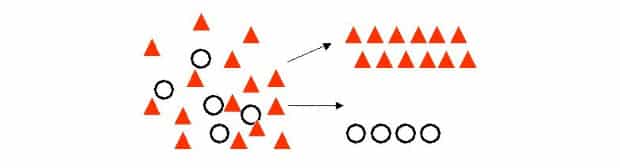
نوع دیگری از مسائل است که ارتباط نزدیکی با طبقه بندی دارد. در این نوع از مسائل و کاربردها، کسی از قبل مسأله را حل نکرده است و خبری از ناظر یا معلم نیست. مثلا، در تئوری های مختلف روان شناسی، افراد به تیپ های شخصیتی مختلف تقسیم بندی می شوند. اما قطعا هیچ یک از این موارد، نه درست هستند و نه غلط؛ فقط یک راه حل هستند برای انجام یک تحلیل. اگر قرار باشد که یک کامپیوتر در نقش یک روانشناس ظاهر شود، می توانیم با یک الگوریتم خوشه بندی، و در دست داشتن اطلاعات شخصیتی چند نفر (مثلا ۱۰ هزار نفر)، که از طریق آزمایش هایی به دست آمده اند، افراد را به (مثلا) پنج خوشه یا Cluster تقسیم کنیم. افرادی که در یک خوشه قرار می گیرند، بیشترین شباهت را به یکدیگر دارند و در عین حال، میان اعضای دو خوشه، کمترین شباهت (بیشترین اختلاف) ممکن وجود دارد. برای انجام این عملیات، که نوعی از یادگیری غیر نظارت شده (Unsupervised Learning) است، الگوریتم های متعددی ارائه شده اند، که تعدادی از آن ها، مبتنی بر روش های الهام گرفته شده از طبیعت هستند؛ مثلا شبکه های عصبی مصنوعی.
-
رگرسیون یا Regression:


خانواده دیگری از مسائل است که در آن بر خلاف مسائل طبقه بندی و خوشه بندی، هدف از حل مسأله رسیدن به یک رابطه ریاضی، برای توصیف یک پدیده است. مثلا، رابطه میان ساعت مراجعه به یک سایت، محل سکونت، سن، سرویس ایمیل مورد استفاده و مقدار سفارش انجام شده توسط یک کاربر. به عنوان یک مثال دیگر، می توان به موضوع پیش بینی سری های زمانی اشاره کرد، که به صورت حالت خاصی از مسأله رگرسیون قابل طرح و حل است.
-
کاوش قواعد وابستگی یا Association Rule Mining:

نیز نوع دیگری از مسائل مطرح شده در داده کاوی هستند، که کاربردهای فراوانی را در هوش تجاری و طراحی سیستم های پیشنهادگر دارند. مثلا، اگر یک فروشنده با تجربه، بگوید که اگر فردی نان و پنیر را در سبد سفارش خود داشته باشد، حتما شیر را نیز انتخاب خواهد کرد، یک قاعده یا Rule مهم را بیان کرده است که بر مبنای آن، می توان تصمیم های زیادی گرفت. مثلا این که، سعی کنیم در چیدمان فروشگاه، حدالمقدور این موارد (نان، پنیر و شیر) در مجاورت یکدیگر باشند. یا این که، می توان یک سیستم پیشنهادگر را می توان بر همین اساس پیاده سازی کرد، که اگر فردی پرینتر رنگی جوهر افشان سفارش داد، به او کارتریج یدکی و یا کاغذ مخصوص چاپ عکس را پیشنهاد بدهد.